Offliner Application
Offliner is an Android app initially made solely for viewing of the ZIP archive of the official Android Developer Docs. It is also capable of browsing other archives created in the same fashion.
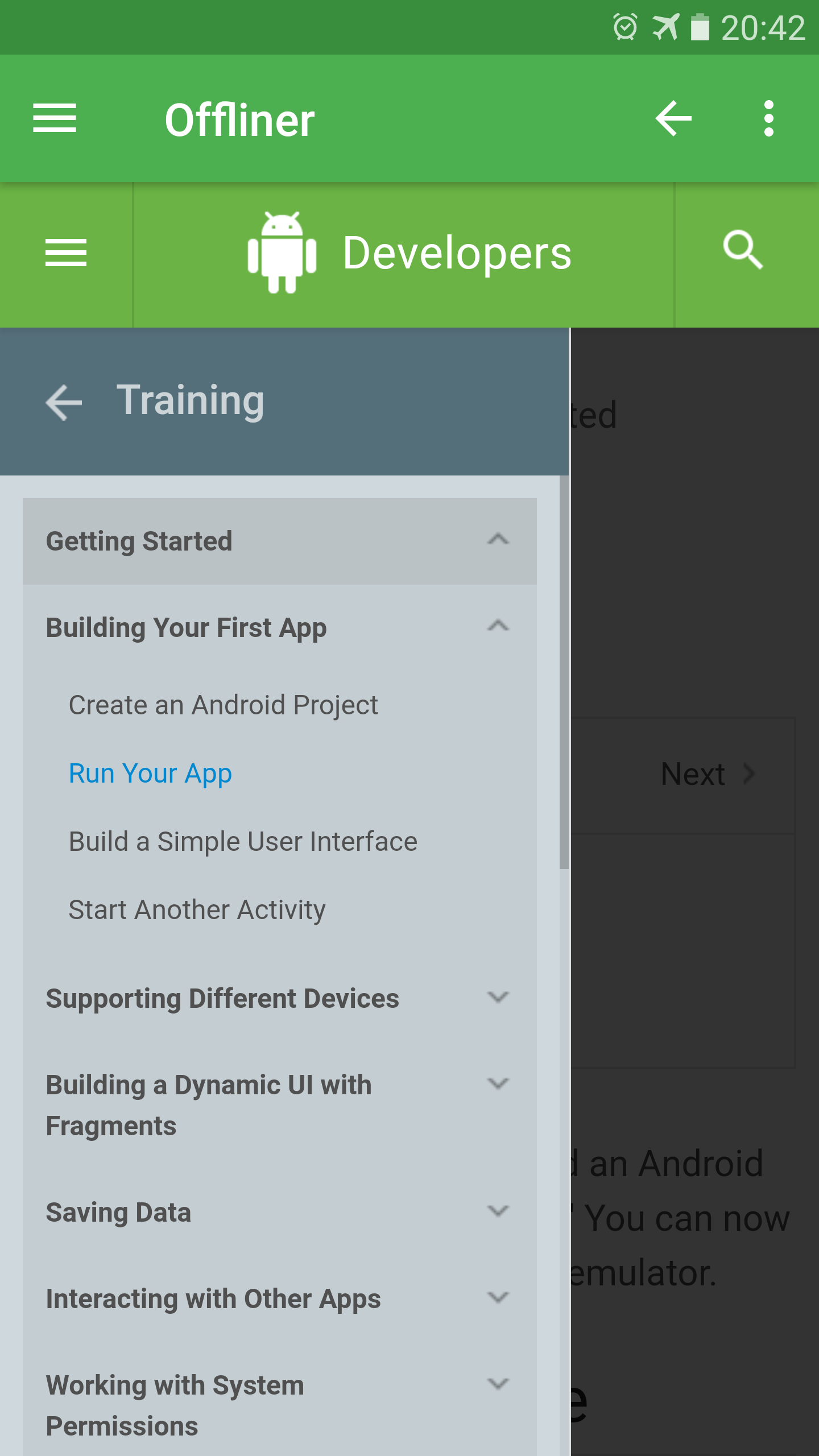
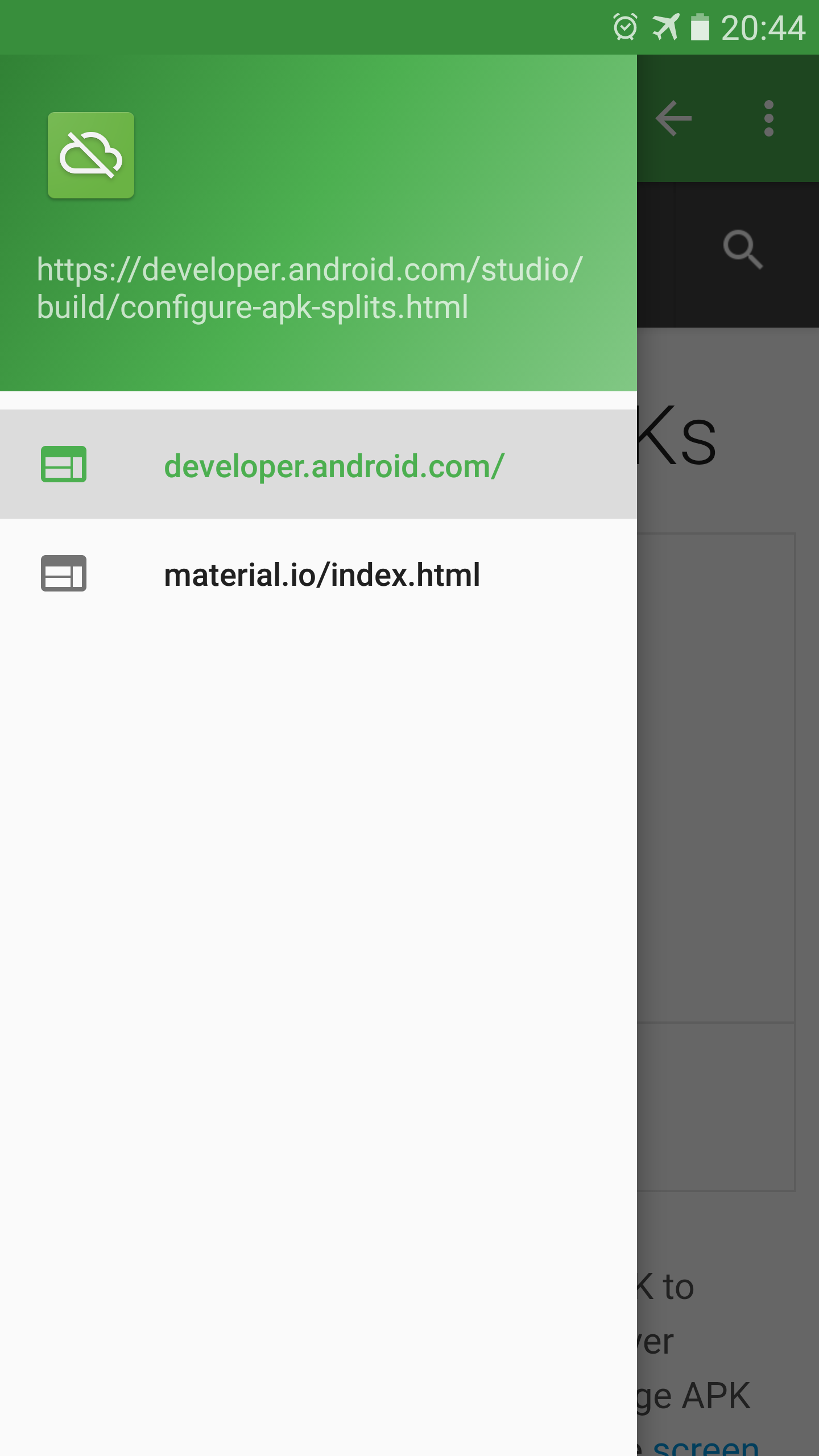
What are the Offliner main features?
- The last page and its position are always saved
- All files are stored compressed inside an packed ZIP files. (Ever tried copying 20 000 files to SD card?)
- Free, without any ads or tracking, no permissions (except for reading storage). It has no access to the internet yet it allows you to open external links in your browser.
- Plain and simple design
- No issues with JavaScript or CORS as all content is served from original domains https – all interactive page components work
- Pages like developer.android.com/reference are unusable in the Chrome browser as they can’t be scrolled horizontally yet they work fine in Offliner
Each fresh start of Offliner can take from few seconds to half a minute depending on your device storage speed and archive size. Use the faster internal memory for storing archives if you want faster loading.
But nothing’s perfect. There are some areas that can be improved:
- Support for wget “–restrict-file-names” to be able to create an archive from Windows machine (it’s filesystem restriction so this includes Cygwin as well)
- Support for httrack “small query string MD5”
- Proper mime type and response code support instead of guessing type based on file extension
- Add support for fullscreen videos
- Investigate possible performance issue when playing embedded html5 videos
Possible (compatibility) problems with a workaround for getting file uri from content uri of a selected file (underlying library requires it for use with RandomAccessFile).Resolved by using 3rd party file chooser- Cache the latest visited content unpacked to internal memory for faster startup (zip loading in background)
To keep things simple, I have no plans adding in-app downloader as even wget/httrack are far from perfect.
![]()
Your feedback is welcome. Please let me know how you use Offliner. Join the discussion at xda-developers.com.
Available Archives
Android Developer Docs
- The official zip from Google, 400 MB, released in 9/2016. By downloading this, your agree to the Android Software Development Kit License Agreement. (The download link can be found inside this XML: http://dl-ssl.google.com/android/repository/repository-12.xml).
Download from http://dl-ssl.google.com/android/repository/docs-24_r01.zip. - Custom wget mirror of developer.android.com & material.io, 1200 MB, 7/2017. This is the full copy of both sites, containing many pages not available in the official offline documentation.
Download from Android File Host or Mega.nz or MediaFire. - Custom wget mirror of developer.android.com, 550 MB, 11/2017.
Download from Android File Host or Mega.nz. - mirror of tldp.org, 59 MB, 8/2017. Checkout great Bash scripting guides.
Download from Android File Host or Mega.nz or MediaFire. - mirror of gnu.org/software/bash/manual, 2 MB, 8/2017.
Download from Android File Host or Mega.nz or MediaFire.
Please note that not everything may work and plenty of links lead outside. But there’s a LOT of content and the majority of it works (including Training, API Guides and other Guidelines).
It it ok to provide these archives? Majority of the content on developers.android.com and material.io is released under Creative Commons or Apache licenses. The whole intention is to have access to the education material that is already available for free. There are no ads in Offliner nor these sites. Search engines or sites like archive.org already provide copies of web sites. That said, everything should be fine.
Custom Archives
These are examples of how the archives were generated. It’s best to use wget 1.19.2; or wget 1.18-1.19.1 and gzip decompression proxy.
# Creates mirror of the developer.android.com and material.io sites wget --mirror --execute robots=off --page-requisites \ --execute use_proxy=yes --execute http_proxy=127.0.0.1:8080 --execute https_proxy=127.0.0.1:8080 --no-check-certificate \ --reject-regex "\.html\?hl=" \ --reject ai,psd,sketch \ --span-hosts --domains=developer.android.com,fonts.googleapis.com,fonts.gstatic.com,material.io,storage.googleapis.com,www.gstatic.com \ --limit-rate=250k \ https://developer.android.com/index.html # workaround for wget not fetching images referenced from JS file grep -Poh '(?<=["'\''])[\/]?images\/[a-zA-Z\/\-\_0-9@]*\.(jpg|png|gif|svg)(?<!["'\''])' developer.android.com/android_metadata_en.js\?v\=201* | sort | uniq > img sed -i '/^\//! s/^/\//g' img sed -i 's|^|https://developer.android.com|' img echo "$(sort img | uniq)" > img wget --force-directories --input-file=img # this should not be needed but not tested yet #grep -Poh '(https://[a-zA-Z\/\-\_0-9@\.]*\.svg)' material.io/icons/webcomponents/first-party.html\?v* > img #wget --force-directories --input-file=img # fetch JSON files required by the icon app wget --force-directories https://material.io/icons/data/grid.json wget --force-directories https://material.io/icons/data/ic_lock_open.json # remove folder with single index.html file (created because of 30x code) rm -rf www.material.io # create archive from all folders in the current directory zip -r dev.zip */
# Creates mirror of the developer.android.com wget --mirror --execute robots=off --page-requisites \ --reject-regex "\.html\?hl=" \ --reject ai,psd,sketch \ --span-hosts --domains=developer.android.com,fonts.googleapis.com,fonts.gstatic.com,storage.googleapis.com,www.gstatic.com \ --limit-rate=500k \ https://developer.android.com/index.html grep -Poh '(?<=["'\''])[\/]?images\/[a-zA-Z\/\-\_0-9@]*\.(jpg|png|gif|svg)(?<!["'\''])' developer.android.com/android_metadata_en.js\?v\=201* | sort | uniq > img sed -i '/^\//! s/^/\//g' img sed -i 's|^|https://developer.android.com|' img echo "$(sort img | uniq)" > img wget --force-directories --input-file=img zip -r developer.android.com-2017-11-20.zip */ -x "developer.android.com/samples/*" -x "developer.android.com/downloads/samples/*"
# Creates mirror of tldp.org wget --mirror --execute robots=off --page-requisites \ --reject bz2,gz,pdf,ps,pdb,rpm,tar,zip \ --exclude-directories=/LDP/LG/,/LDP/LGNET/,/pub/Linux/docs/HOWTO/translations/,/pub/Linux/docs/ldp-archived/ \ --limit-rate=500k \ http://tldp.org/index.html zip -r tldp.zip tldp/
# Creates mirror of gnu.org/software/bash/manual wget --mirror --execute robots=off --page-requisites \ --no-parent \ --limit-rate=500k \ https://www.gnu.org/software/bash/manual/ zip -r gnu-bash-manual.zip www.gnu.org/
# Creates mirror of docs.ansible.com/ansible/latest wget --mirror --execute robots=off --page-requisites \ --exclude-directories=/ansible-tower/,/ansible-container/ \ --span-hosts --domains=docs.ansible.com,cdnjs.cloudflare.com,fonts.googleapis.com,fonts.gstatic.com,storage.googleapis.com,www.gstatic.com \ --limit-rate=500k \ http://docs.ansible.com/ansible/latest/index.html rm -rf docs.ansible.com/index.html rm -rf docs.ansible.com/ansible/index.html zip -r ansible.zip */
In the navigation drawer (left side menu), Offliner lists all folders/sites with an index.html file.